RAG Application with Azure AI Studio and Facebook AI Similarity Search

Introduction
The advent of big data has presented us with the challenge of effectively managing and extracting valuable insights from vast amounts of text. The key lies in transforming this text into a searchable format while maintaining efficient retrieval capabilities. Furthermore, systems must be able to interact with humans, understanding semantics despite variations in language use. A crucial aspect is also the ease of developing applications based on this framework.
A promising solution to these challenges is the Retrieval-Augmented Generation (RAG) framework. In the past, implementing RAG was complex and involved extensive coding. However, recent advancements, particularly with Azure Cloud’s Azure AI Studio, have simplified the development of RAG applications significantly. This article explores the experience of using Azure Machine Learning Studio for RAG application development, highlighting key aspects like vectorization and the use of the Prompt Flow tool in Azure AI Studio. The article concludes with insights into testing and deployment.

Understanding RAG
RAG combines retrieval-based and generative models in natural language processing, such as Large Language Models (LLMs). This framework enriches the language model’s responses with information retrieved from a large corpus of documents.
The Importance of Vectorization and Vector Transformation
A central component in RAG is vectorization, where text is converted into numerical vectors. This is crucial for machines to process and understand human language. FAISS (Facebook AI Similarity Search), a library designed for efficient similarity search and clustering of dense vectors, plays a significant role in this context. FAISS is especially useful for large-scale information retrieval.
The process involves two main steps:
- Vectorization — Transforming text into numerical vectors using models like ‘text-embedding-ada-002’.
- Vector Transformation with FAISS — Once in vector form, FAISS indexes these vectors for quick and accurate searching and retrieval.
For example, a sentence like “Sunny weather brightens my mood” is transformed into a numerical array and then indexed using FAISS for efficient retrieval.
Essential Components for Implementing RAG
To effectively implement RAG, several key components must work together:
- Document Corpus: This is the foundational element of any RAG system. It consists of a large collection of text documents which the system uses as a source to retrieve relevant information. The size and quality of this corpus directly impact the system’s ability to provide accurate and relevant responses.
- Document Encoder: This component is responsible for transforming the textual content of documents into vector representations within a vector space. The use of FAISS (Facebook AI Similarity Search) for indexing and optimizing these vectors is crucial. It significantly enhances the search speed and accuracy, allowing the system to quickly locate and retrieve documents that are most relevant to the user’s queries.
- Question/Query Encoder: Similar to the Document Encoder, this component converts user queries or searches into vector representations. Utilizing FAISS in this stage can further refine the search process, enabling the system to more effectively compare and locate the most relevant documents based on the user’s input.
- Retrieval System: This system is tasked with searching through the document corpus. It often involves complex indexing and semantic search algorithms to efficiently retrieve information. FAISS is a common choice for this purpose due to its efficiency in handling large datasets and its ability to perform fast similarity searches.
- Large Language Models (LLMs): Models like GPT or T5 are used here. This component takes the input queries and the information retrieved from the document corpus to generate coherent and contextually relevant responses. The generative model synthesizes the information in a way that is comprehensible and informative for the user.
Together, these components form a robust system capable of handling large volumes of text data, understanding user queries, and generating accurate and contextually relevant responses. The integration of FAISS across different stages further enhances the system’s performance, particularly in terms of search efficiency and accuracy.
Implementing RAG with Azure AI Studio
Developing AI applications using the RAG framework can be accomplished using Azure AI Studio (and Azure ML Studio at the time of writing this article), which involves three main steps:
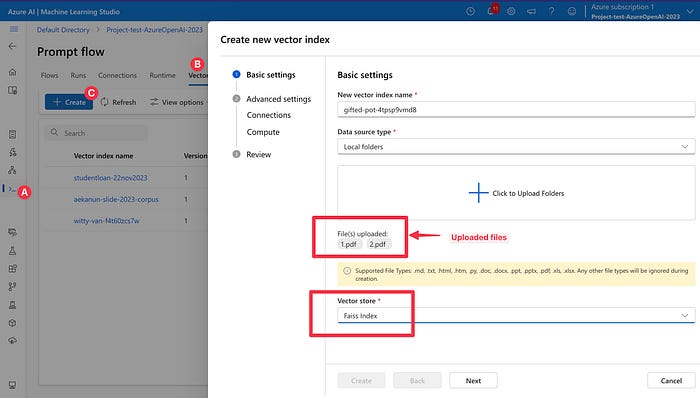
Step 1: Importing Data (Corpus) into Vector Store — Start by selecting the Prompt Flow menu (A), then click on the “Vector Index” tab (B). Next, choose “Create” ©. This step involves uploading a document file (like PDF) and setting up a VM for processing. The final step is to define the “Vector store” as a Faiss index as shown in Figure 1.
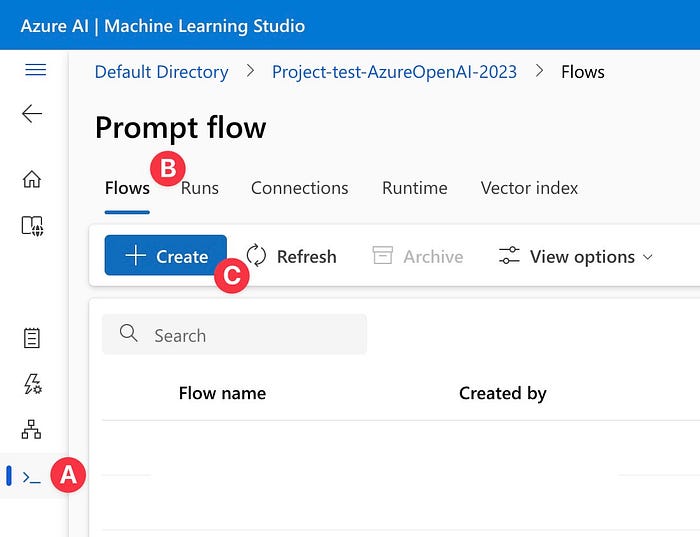
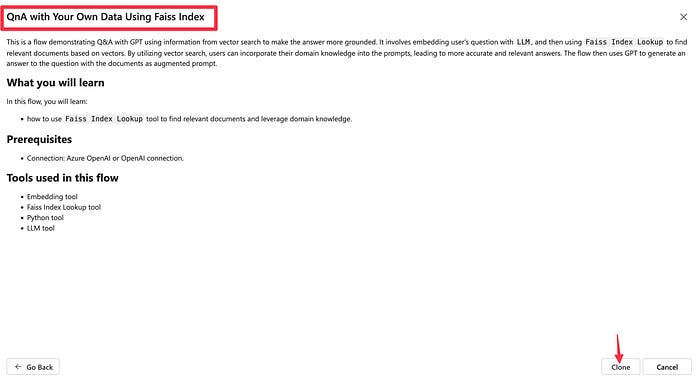
Step 2: Developing AI Application — Begin by selecting the Prompt Flow menu (A), then click on the “Flow” tab (B). Next, choose “Create” ©. In this article, the selected option is “QnA with Your Own Data Using Faiss Index,” designed to answer questions using your own dataset, with the aid of a FAISS index as shown in Figures 3 and 4.
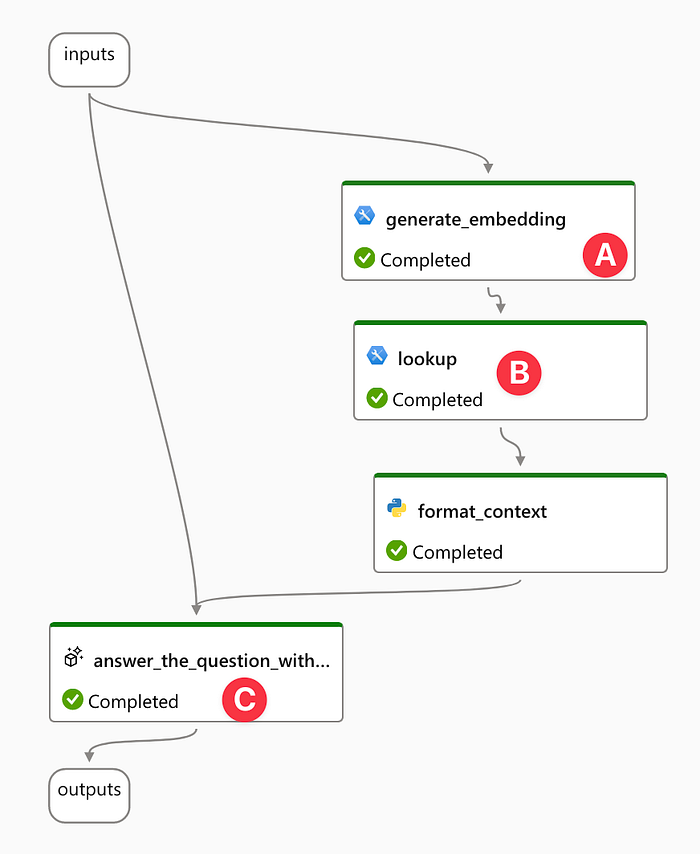
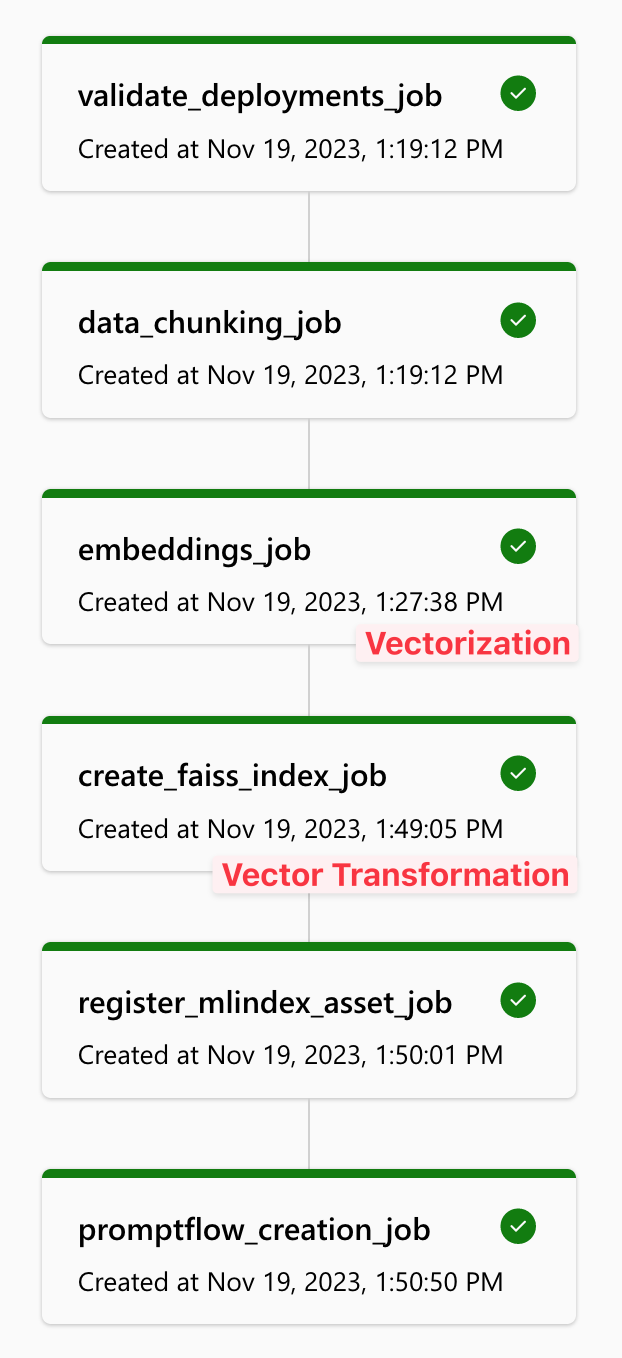
When selecting “QnA with Your Own Data Using Faiss Index,” Azure automatically provides a Flow consisting of components like input, generate_embedding, lookup, format_context, and answer_the_question_with_context. In this article, you simply need to define a starting question, such as “Do you know Hamas?” in the input, choose “text-embedding-ada-002” in generate_embedding, specify the URL of the Vector Store from Step 1, and select “gpt-35-turbo” in answer_the_question_with_context. Then, “Add runtime” and click “Run” to get the workflow as shown in Figure 5.
- The flow utilizes vector search to ground the answers in information retrieved from a vector space, which likely improves the relevance and accuracy of the answers.
- It involves embedding the user’s question using a Large Language Model (LLM) — “text-embedding-ada-002”, which translates the question into a vector. (A)
- After the question is embedded, the FAISS Index Lookup tool is used to find relevant documents based on vectors. This step involves searching through an indexed database of vectors (which represent documents) to find the closest matches to the query vector. (B)
- Once the relevant documents are retrieved, the system uses GPT (gpt-35-turbo) to generate an answer. GPT can take into account the information from the retrieved documents to provide an answer that is both relevant to the query and informed by the document content. (C )
Step 3: Application Deployment and Getting an Endpoint
After completing the development of AI applications and being able to run the flows successfully, on the same screen as the Flow, click on the “Deploy” button. A dialog box will appear allowing you to set the VM and the number of VMs (Instance count) for Application deployment in real-time inference for testing purposes. There will also be APIs code for future practical use. Once the Application deployment process is finished, you will obtain an Endpoint.
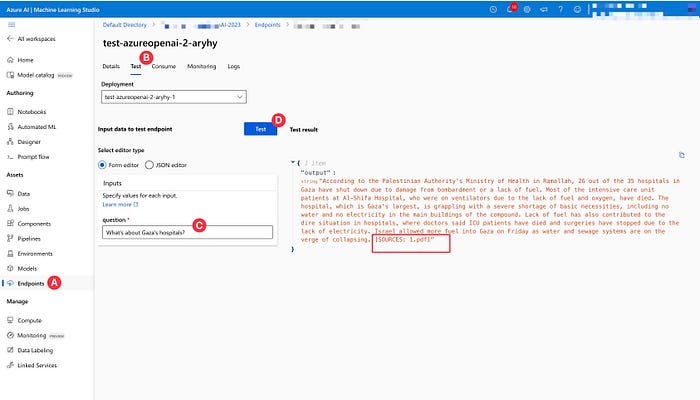
As shown in Figure 6, the steps for using the Endpoint begin with selecting the “Endpoints” menu (A), then choosing the “Test” tab (B), and trying to write a question to test, such as “What’s about Gaza’s hospital?” ©. The Endpoint will then provide an answer that corresponds to the question. Interestingly, the Endpoint also displays the name of the document that we previously uploaded into the Vector store. Moreover, at the “Consume” tab, there is Python Code for setting up APIs that can be used for production with tools like “Streamlit”.

Conclusion
The exploration of the Retrieval-Augmented Generation (RAG) framework, as facilitated by Azure AI Studio and enhanced by Facebook AI Similarity Search, marks a significant advancement in the field of text analytics and natural language processing. This integration not only simplifies the once complex task of implementing RAG but also opens up a myriad of possibilities for its application across various industries.
The transformative power of RAG lies in its ability to seamlessly blend retrieval-based and generative models, offering a nuanced approach to understanding and responding to human language. The use of vectorization, with the pivotal role of FAISS in efficiently indexing and retrieving information, underscores a remarkable leap in processing large volumes of data with precision and speed.
Practical applications, ranging from enhanced customer service chatbots to sophisticated legal document analysis, illustrate the versatility and potential of RAG. Furthermore, its implications in fields like healthcare, research, and digital content creation point towards a future where AI not only understands but intelligently interacts with human language.
As we look ahead, the continuous evolution of RAG, particularly in terms of ethical AI use, privacy considerations, and cultural adaptability, will be crucial. The integration of RAG with emerging AI technologies promises not only more advanced applications but also a deeper understanding of the complexities of human language and knowledge.
In conclusion, the implementation of RAG, streamlined by tools like Azure AI Studio and augmented by libraries like FAISS, represents a significant stride in our journey towards more intelligent, responsive, and context-aware AI systems. This journey, while complex and ever-evolving, is essential in our quest to harness the full potential of AI in understanding and augmenting human capabilities.
References
[1] Get started with RAG using a prompt flow sample (preview), https://learn.microsoft.com/en-us/azure/machine-learning/how-to-use-retrieval-augmented-generation?view=azureml-api-2
[2] Faiss: A library for efficient similarity search, https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/
